whisper
whisper
OpenAI 开源 Whisper,目前最精确的 AI 语音识别模型。
语音转文字有很多种方法。首先,可以当个「工具人」自己手动转录,这样可以获得最高的准确性,但费时费力。其次,可以使用服务或工具。例如,可以将视频上传到 YouTube,让它自动生成字幕,或者使用「剪映」这类工具来生成字幕,然后再手动校对。
如今,有多种 AI 工具可以出色地完成语音转文字,其中最精确之一便是 OpenAI 推出的 Whisper 语音识别模型。Whisper 具有高达 95% 的准确率,是内容创作者、采访转录人员和音频转文字用户的理想选择。
什么是 Whisper
Whisper 是一个由 OpenAI 开发的通用语音识别模型(ASR),在大量多样化的音频数据集上进行训练,具有惊人的准确性。它同时也是一个多任务模型,可以执行多语言语音识别、语音翻译和语言识别。OpenAI 已经将 Whisper 开源,供社区使用。
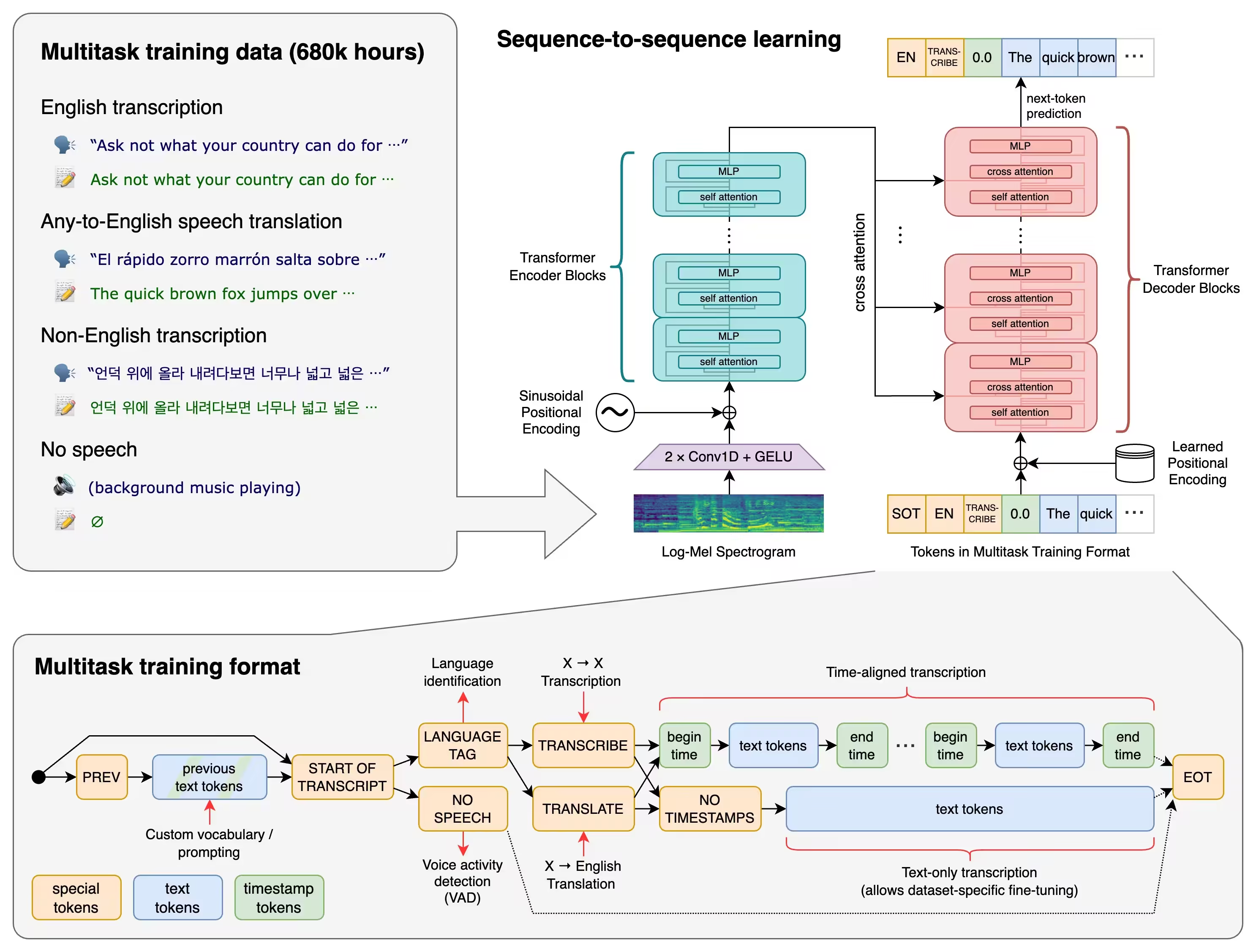
Whisper 的工作原理非常先进,涉及对来自互联网的 68 万小时的有监督数据进行训练(其中三分之一不是英语)。音频被分割成 30 秒的片段,然后转换为 log-Mel 频谱图,传递给一个编码器。经过训练的解码器会尝试预测相应的文本字幕。此外,还有其他技术性步骤,涉及识别所说的语言、多语音转录以及翻译成英语。
OpenAI 表示,Whisper 的错误率最多比其他语言模型低 50%,但它并不是面向最终用户的工具,而是为开发人员和研究人员设计的。开源模型和代码的目的是为了「作为构建有用的应用程序和进一步研究稳健语音处理的基础」。我们虽然可以设置并使用它,但它实际上并不是一个真正的消费级产品。
在语音转文本时,有多个模型可供选择,每个模型的 GPU 显存需求也不一样。最大的 large 模型需要 10 GB 的显存,也是最准确的。除了 large 模型外,其它模型都有「仅英语」版本,如果已经明确要转录的内容只是英语,则可以减少显存需求。但不管如何,都需要一块性能良好、具备足够显存的 GPU 才能良好运行 Whisper。
如何使用 Whisper
Whisper 已经被 OpenAI 开源,可以很容易地跑起来:
- 可以在 Google Colab 中运行 Whisper,但速度较慢。
- 使用 Apple 芯片的 Mac 用户,需要自己从源代码编译一个 Whisper.cpp,虽然这不是官方移植,但这是在 Apple 芯片上本地运行的唯一方法。可以参考如何在 Mac 上安装 Whisper。
- 使用 x86 架构的计算机,也可以在本地运行它。需要安装 ffmpeg,并按照 Whisper Git 存储库中的说明进行操作,就能很快设置好 Whisper。
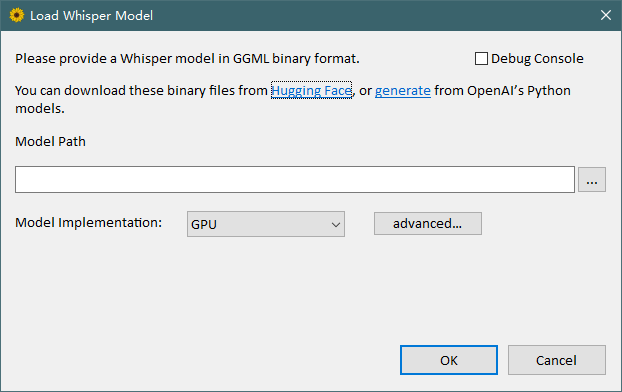
对于广大怕麻烦的 Windows 用户,可以下载编译好的 WhisperDesktop.zip 图形界面版使用,该项目是 Whisper.cpp 实现的 Windows 移植版,而 Whisper.cpp 是 OpenAI Whisper 自动语音识别模型的 C++ 移植版。
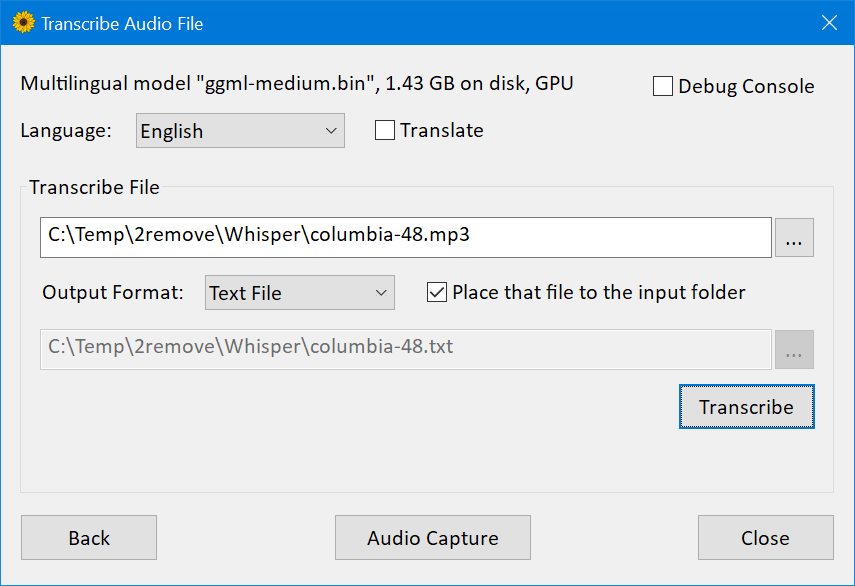
Download WhisperDesktop.zip from the “Releases” section of this repository, unpack the ZIP, and run WhisperDesktop.exe.
On the first screen it will ask you to download a model.
I recommend ggml-medium.bin (1.42GB in size), because I’ve mostly tested the software with that model.
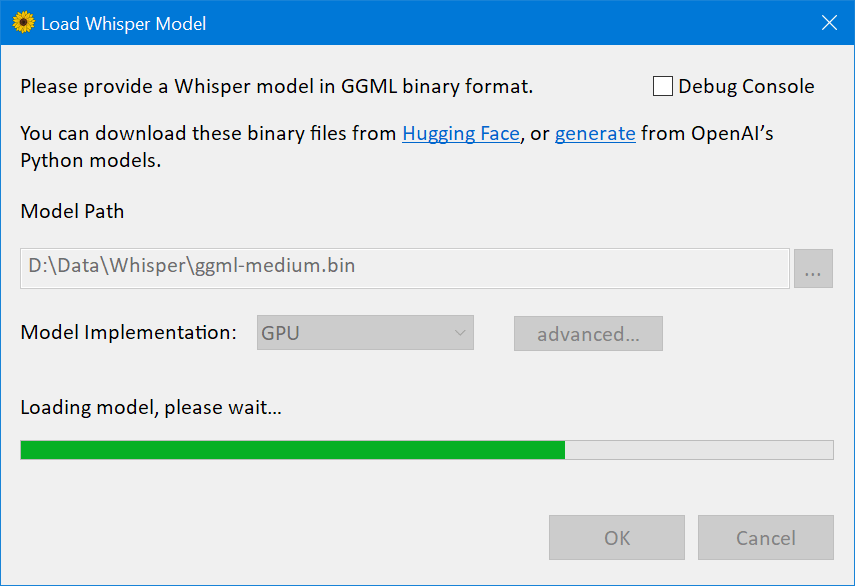
The next screen allows to transcribe an audio file.
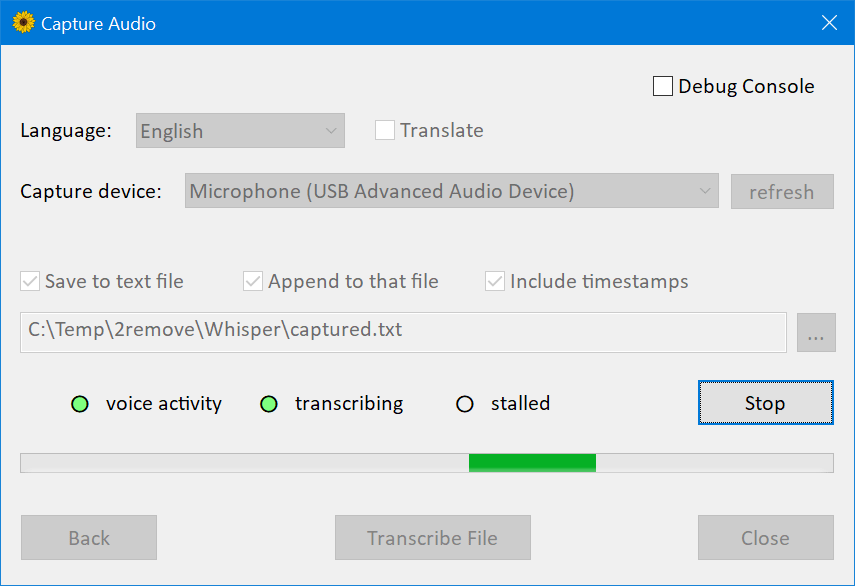
There’s another screen which allows to capture and transcribe or translate live audio from a microphone.