Kettle的使用
windows安装很方便,下载一个jdk。下载下软件开即可。
软件下载地址
找起来还挺复杂
社区版官网下载地址Pentaho Community Edition Download (hitachivantara.com) 打开界面点击 Download ,向下滚动选择版本

下载下来解压到文件夹即可,win 打开 Spoon.bat 就会启动图形界面。Linux 打开 spoon.sh
界面如下:
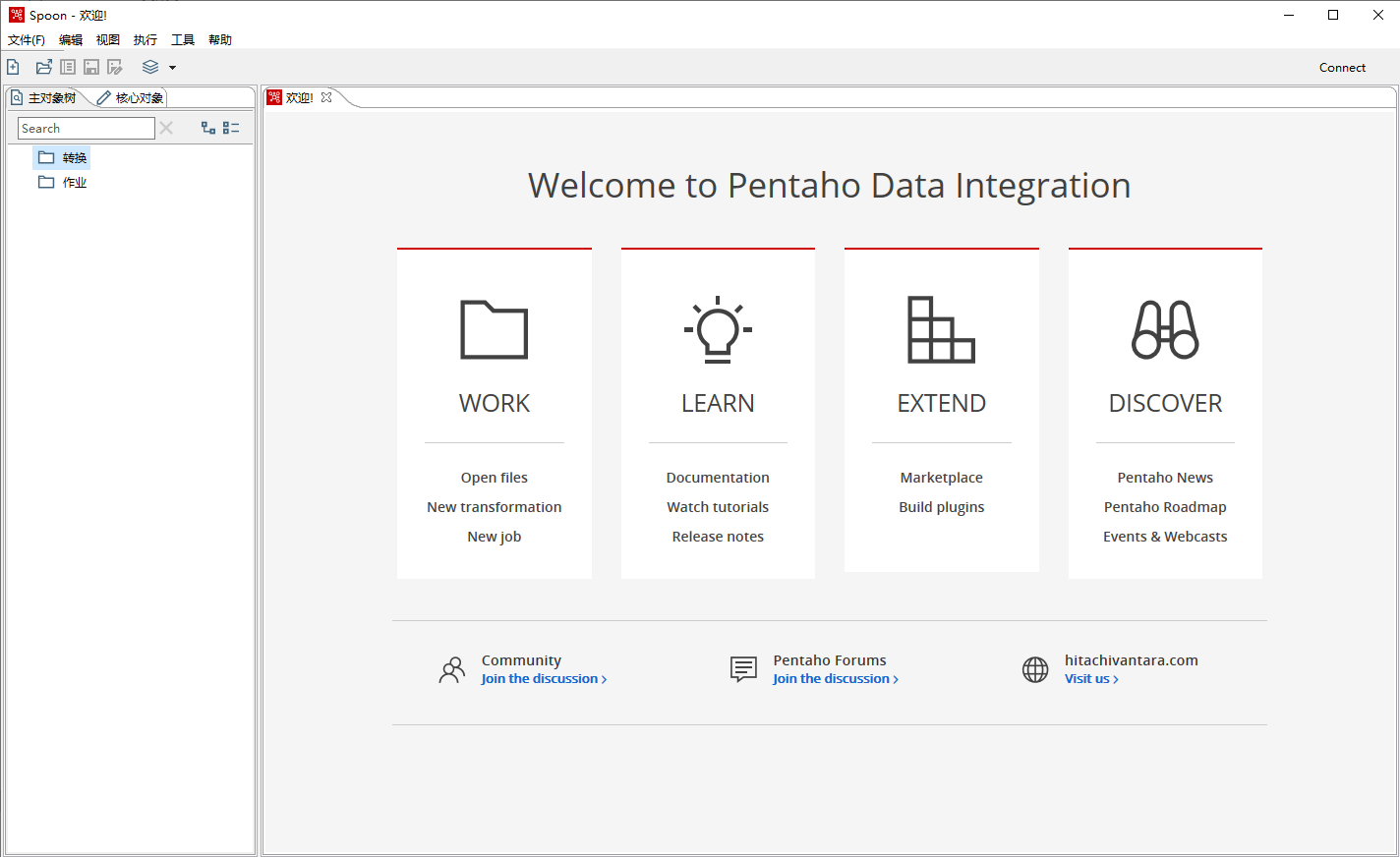
Kettle 初体验
将 csv 文件转为 Excel 文件
- 在 Kettle 中新建一个转换,然后选择转换下面的 “csv 文件输入”和“Excel 输出”控件,拖到右侧空白界面
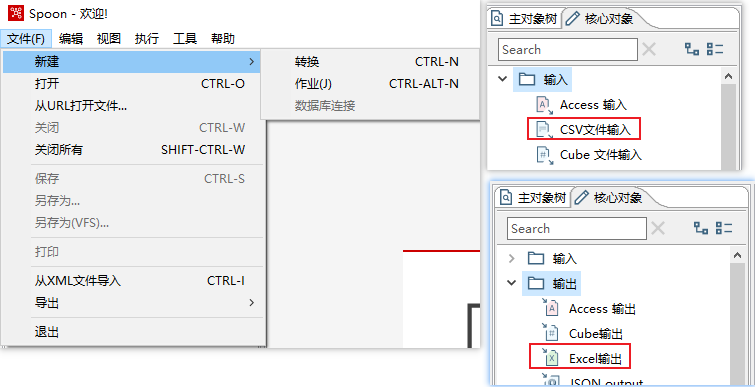
- 双击CSV文件输入文件控件,在弹窗的设置框里找到对应的csv文件,然后点击下面的获取字段按钮,将我们需要的字段加载到kettle中。
CSV文件样例,创建一个文本,后缀改成csv
id,name,age,sex
1,zhangsan,20,0
2,lisi25,0
3,wangwu,24,1
4,zhaoliu,26,1
5,ssfida,8,0
- 按住键盘 Shift 键,并且点击鼠标左键将两个控件链接起来,链接时选择“主输出步骤”
- 双击 Excel 输出设置格式,==宽度设为0表示不要小数==

- 按钮或 Ctrl + s 保存这个转换
- 页面左上运行这个转换,弹出框里点击“启动”
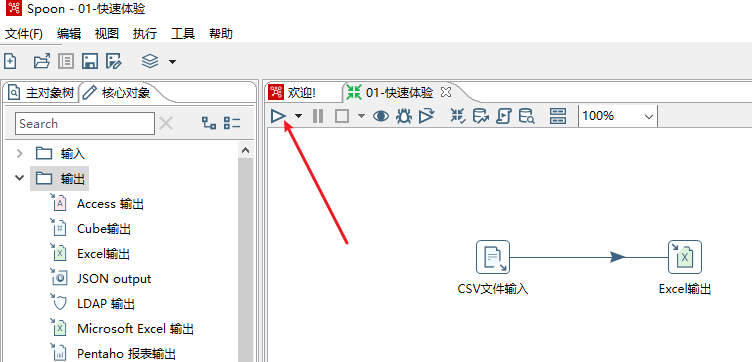
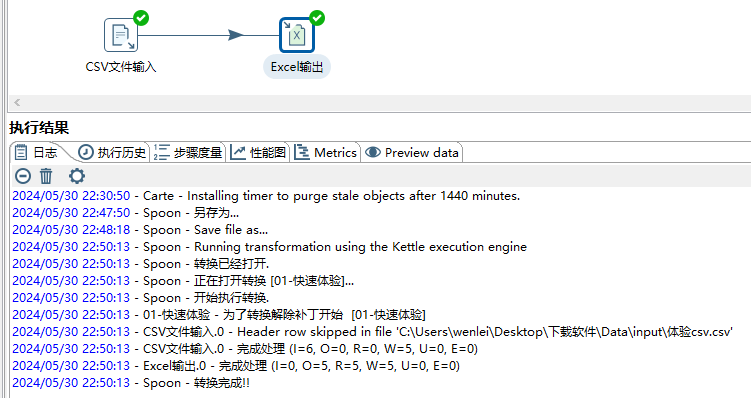
- 会显示日志
核心概念
转换
转换(Transaformation)负责数据的输入、转换、校验和输出等工作。Kettle中使用转换完成数据 ETL 全部工作。转换由==多个步骤(Setp)==组成,如文本文件输入、过滤输出行、执行SQL脚本等。各个步骤使用==跳(Hop)==来链接。跳定义了一个数据流通道,即数据由一个步骤 流(跳) 向下一个步骤。在Kettle中数据的最小单位是数据行(row),数据流中流动的其实是缓存在==行集(RowSet)==
步骤
步骤控件是转换里的基本的组成部分,快速入门的案例中就存在2个步骤“CSV输入”和“Excel输出”。
一个步骤有如下几个关键特性:
- 步骤需要有一个名字,这个名字在同一个转换范围内唯一
- 每个步骤都会读、写数据行(唯一例外的是“生成记录”步骤,该步骤只写数据)
- 步骤将数据写到与之相连的一个或多个输出跳,再转送到跳的另一端的步骤
- 大多数的步骤都可以有多个输出跳。一个步骤的数据发送可以被设置为分发和复制,(分发是目标步骤轮流接收记录,复制是所有记录被同时发送到所有目标步骤)
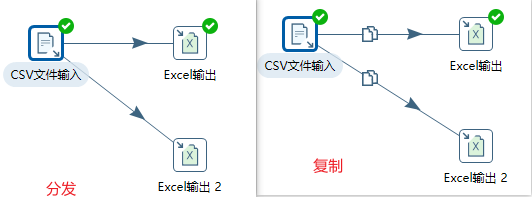
跳
跳就是步骤之间带箭头的连线,跳定义了步骤之间的数据通路。
跳实际上是两个步骤之间被称为行集数据行缓存,行集的大小可以在转换的设置里定义。当行集满了,向行集写数据的步骤将停止写入,直到行集里又有空间。当行集空了,从行集读取数据的步骤停止读取数据,直到行集里又有数据可读的数据行。
元数据
每个步骤在数据行时都有对应字段的描述,这个描述就是数据行的元数据
通常包含下面信息:
- 名称:数据行里的字段名是唯一的
- 数据类型:字段的数据类型
- 格式:数据的显示方式,如Integer
- 长度:字符串的长度或者BigNumber类型的长度
- 精度:BigNumber数据类型的十进制精度
- 货币符号:¥
- 小数点符号:十进制数据的小数点格式。不同文化背景下小数点符号是不同的
- 分组符号:数值类型数据的分组符号,不同文化背景下数字里分组符号不同一般是点或逗号或单引号
数据类型
数据以数据行的形式沿着步骤移动,一个数据行是零到多个字段的集合,字段包含下面几种数据类型。
- String:字符类型
- Number:双精度浮点数
- Integer:带符号长整形
- BigNumber:任意精度数据
- Date:带毫秒精度的日期值
- Boolean:true和false的布尔值
- Binary:二进制字段可以包含图像、声音、视频以及其他二进制数据
并行
跳的这种基于行集缓存的规则允许每个步骤都是由一个独立的线程运行,这样并发程度最高。这一规则也允许数据以最小消耗内存的数据流的方式来处理。在数据仓库里,我们经常需要大量数据,所以高并发低消耗的方式也是 ETL 工具的核心需求。
对 Kettle 转换,不能定义一个执行顺序,因为所有步骤都是以并发方式执行:当转换启动后,所有步骤都同时启动,从他们的输入跳中读取数据,并把处理过的数据写到输出跳,直到输入跳里不再有数据,就终止步骤的运行。当所有步骤都终止,整个转换就终止。
如果想要一个任务沿着指定的顺序执行,那么就要使用“作业”
作业
作业(Job)负责定义一个完成整个工作流的控制,比如将转换的结果发送邮件给相关人员。因为转换以并行的方式执行,所以必须存在一个串行的调度工具来执行转换,作业就是这个功能。
输入控件
输入是转换里第一个分类,输入空间也是转换中的第一大控件,用来抽取数据或者生成数据。输入是ETL里面 E(Extract),只要做数据提取工作。
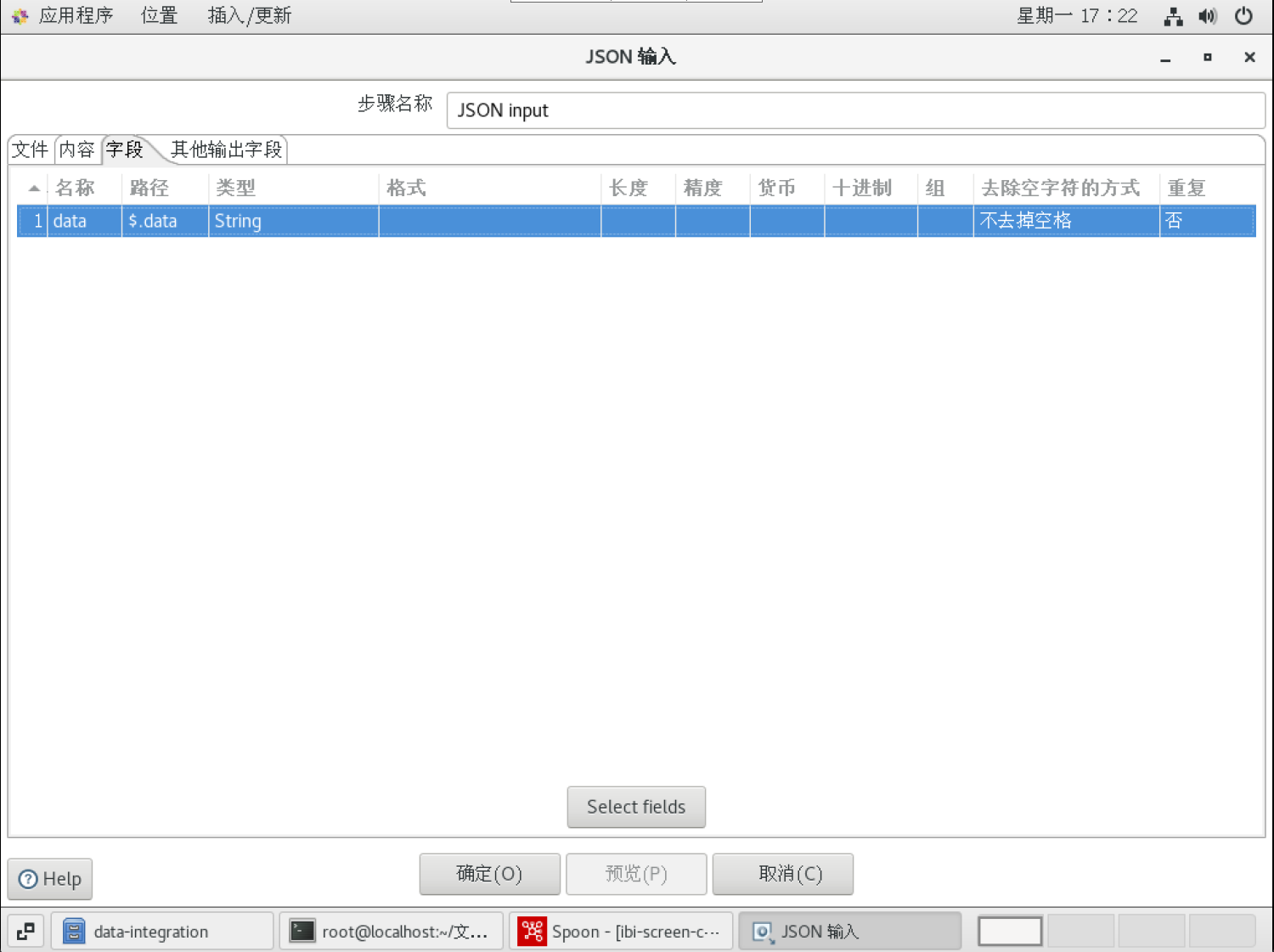
JSON输入

选择对应的字段,并取出来
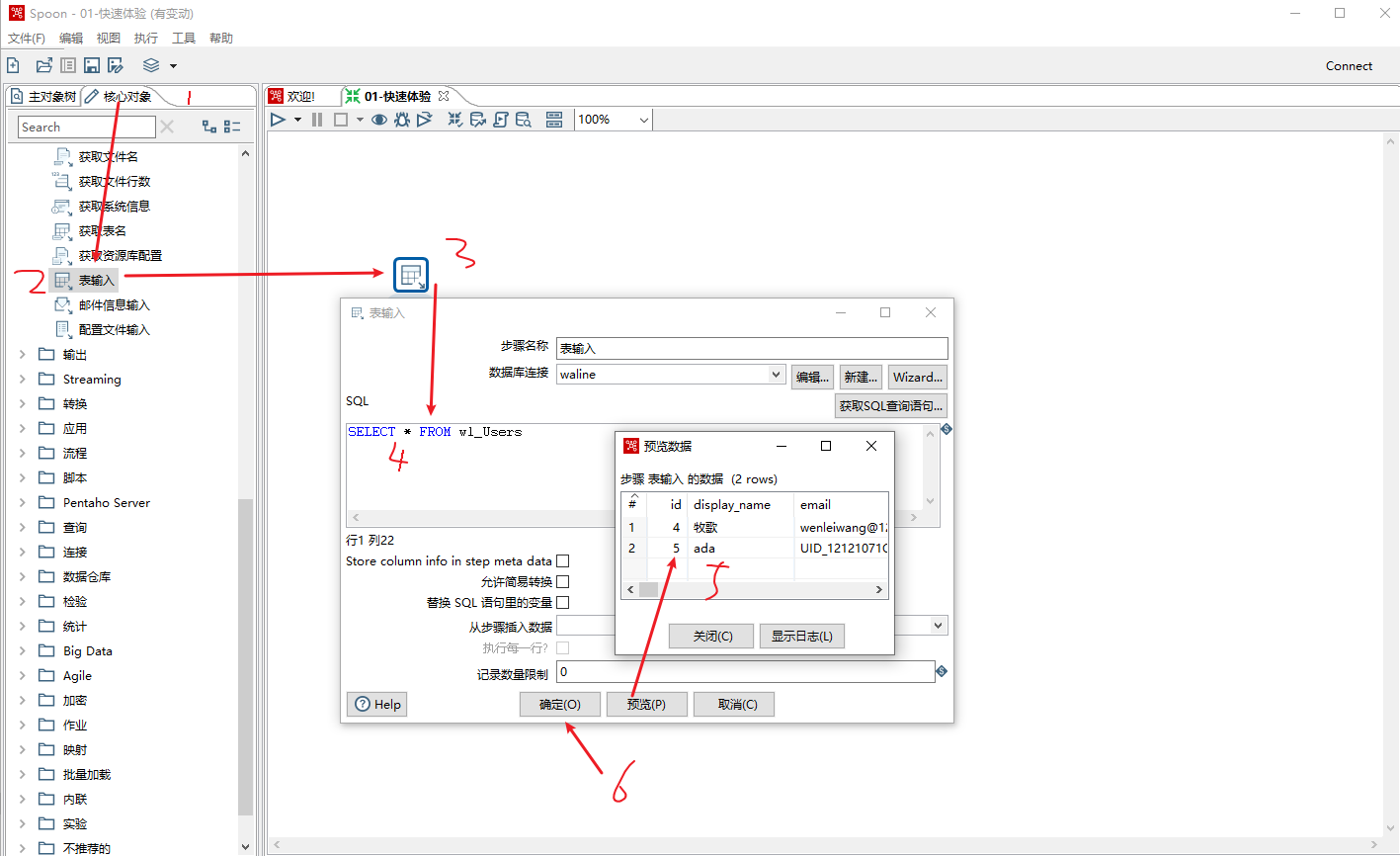
表输入
创建数据库连接
表输入可以说是 Kettle 中用到最多的一种输入空间,因为企业中大部分数据都会存在数据库汇总。Kettle可以连接市面上常见到的各种数据库,如Oracle、MySQL、SqlServer等。但在连接各个数据库之前,我们需要先配置号对应的数据库驱动,以MYSQL为例,学习kettle连接mysql数据库的过程。
首先将对应版本mysql连接驱动放到kettle安装目录的lib文件夹下,然后重启kettle的客户端。
重启客户端以后,我们就可以创建对应的数据库链接了,在转换试图对应主对应树目录下有个DB连接,右键选择新建,在打开数据库连接框里,填写正确的数据库信息,然后测试,测试无误后,可以保存此数据库连接。

链接完成会在DB连接下面出现配置的数据库
使用表输入
输出控件
Excel 输出
kettle 中自带了2个 Excel 输出, 一个 Excel 输出,一个 Microsoft Excel 输出。
Excel 输出只能输出 xls 文件,Microsoft Excel 输出可以输出 xls 和 xlsx 文件
文本文件输出
选择分割符号
Json输出
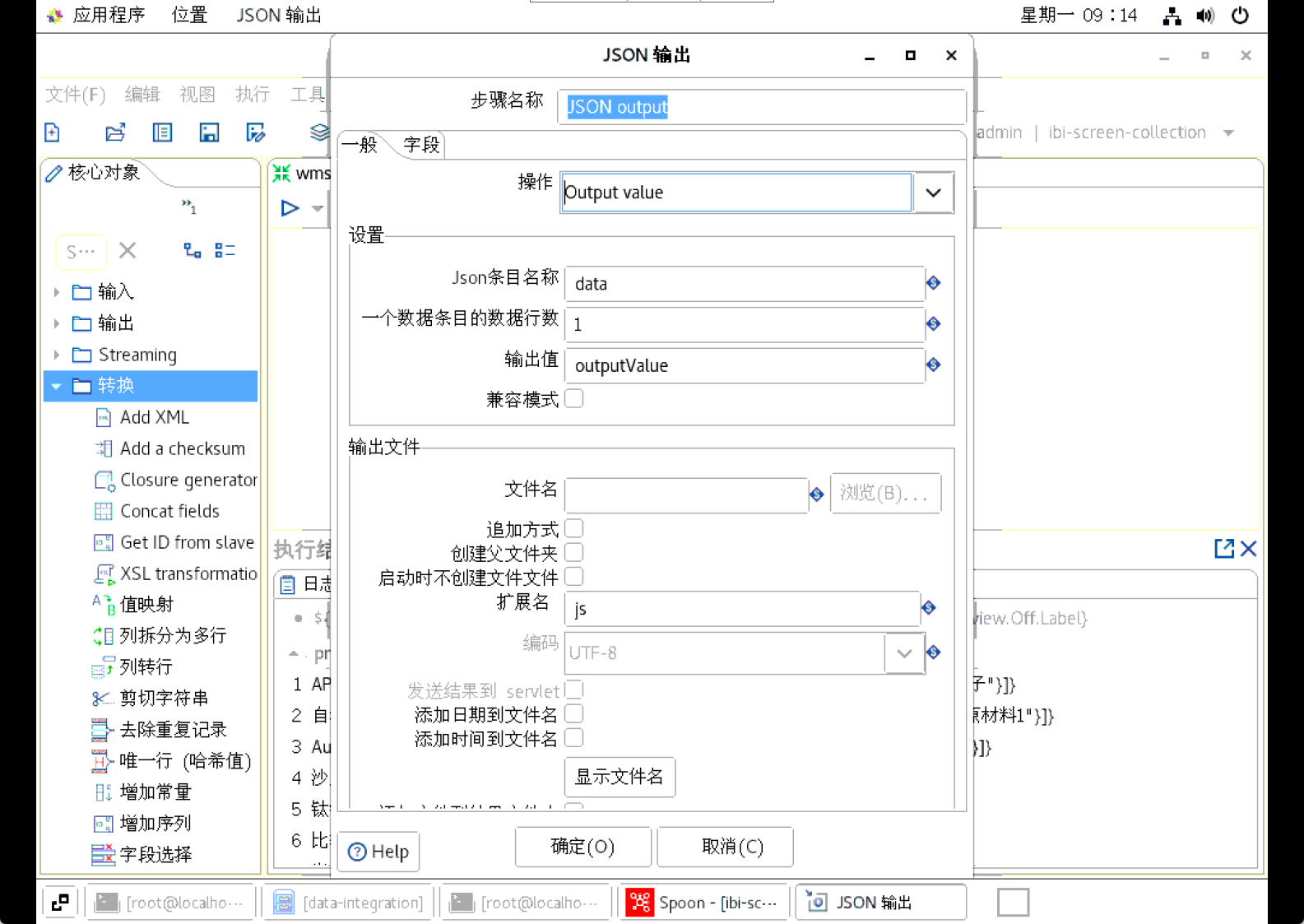
目前kettle自带的json Output 可以支持三种输出模式
- 输出json字符串的值
- 以json格式写入到文件
- 输出json格式的值,同时写入数据到指定文件
设置说明
Json条目名称:用来配置生成的json数据的键的, 可参考下面的json格式, 这里默认是data
一条数据条目的数据行数:一个数据条目的数据行:用来配置data中有多少个json串,如果设置为不为0的数, 那么就会生成多个文件,每个文件中的json有指定数量的子json串,如果不设置值, 所有数据都会在同一个文件中
输出值:生成json串在后面使用时如何调用, 这里配置的是变量字段的名称
SQL文件输出
SQL文件输出一般跟表输入做连接,然后将数据库里面的表结构和数据以 sql 文件的形式导出,然后做数据库备份的工作。
- 选择合适的数据库连接
- 选择目标表
- 勾选增加创建表语句和每一个语句另起一行
- 填写输出文件的路径和文件名
- 扩展默认为sql
varchar 需要注意一下
表输出
表输出控件可以将 kettle 数据行中的数据直接写入到数据库中的表中,企业里做ETL 工作会经常用到此控件。
- 选择合适的数据库连接
- 选择目标表,目标表可以提前在数据库中手动创建好,也可以输入一个数据库不存在的表,然后点击下面的SQL按钮,利用kettle现场创建
- 如果目标表的表结构和输入数据的数据结构不一致,可以自己指定数据库字段
首次运行的时,有可能报下面的错误,其中一个可能原因是:本机安装的mysql软件版本与放置在Kettle软件lib文件夹里的数据库驱动版本不一致。
You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'OPTION SQL_SELECT_LIMIT=DEFAULT' at line 1
解决方案是,因为我用的是最新版本的mysql,所以到官网下载了一个最新的驱动jar包,替换上就OK了。
更新&插入/更新
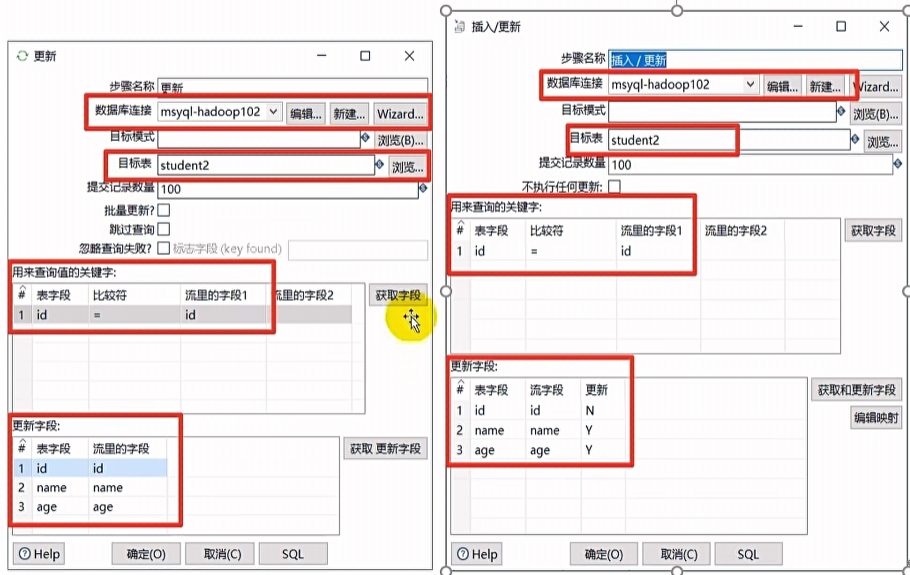
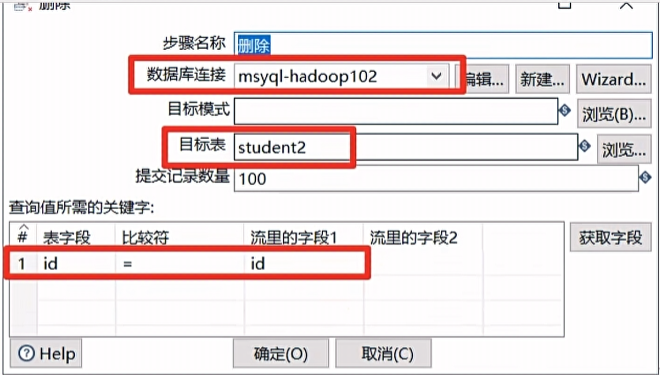
删除
删除控件可以删除数据库表中指定条件的数据,企业里一般用此控件做数据库表数据删除或者跟另一个表数据做对比,然后进行去重的操作。
- 选择数据库连接
- 选择目标表
- 设置数据流跟目标要删除数据的对应字段
转换控件
转换控件是转换里面的第四个分类,转换控件也是转换中的第三大控件,用来转换数据。转换是ETL里的T(Transform),主要做数据转换、数据清洗工作。ETL整个过程中,Transform的工作量最大,耗时较久,大概占到整个ETL的三分之一。
常用控件
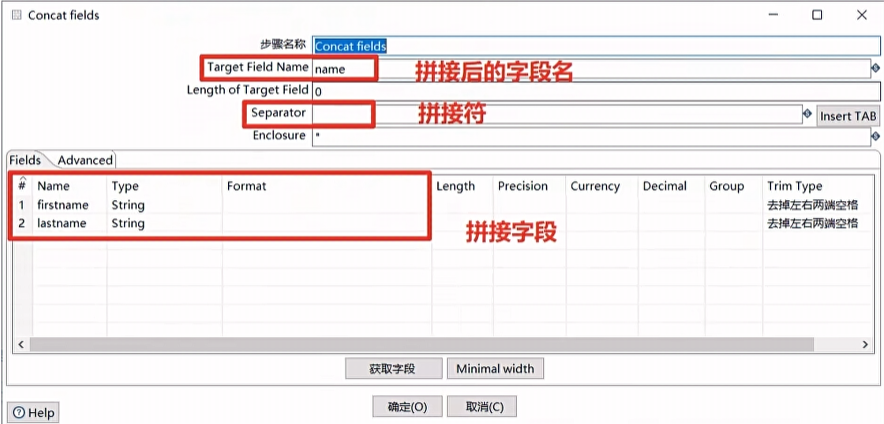
Concat fields
将多个字段链接起来形成一个新字段
提示:MYSQL中文乱码是数据库配置问题
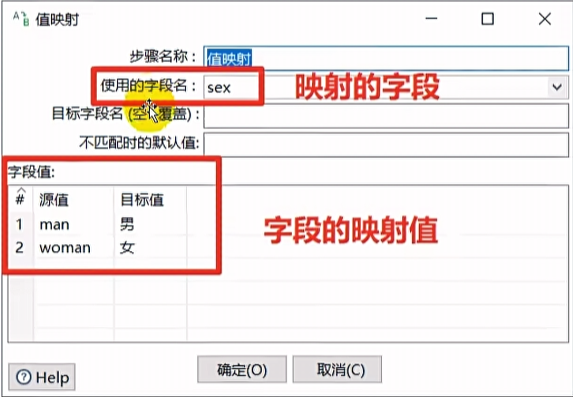
值映射
值映射就是就是把一个值映射成其他的值。在数据质量规范上使用非常多,比如很多系统对应性别 sex 字段的定义不同。所以我们需要利用此控件,将同一个字段的不同的值,映射转换成我们需要的值。
增加常量&增加序列
增加常量就是在本身数据流里面添加一列数据,该列的数据都是相同的值。
增加序列是给数据流添加一个序列字段,可以自定义该序列的递增步长。

字段选择
字段选择是从数据流中选择字段、改变名称、修改数据类型。
注意:获取选择的字段按钮
计算器
计算器是一个==函数集合==来创建新的字段,还可以设置字段是否移出(临时字段),可以通过计算器里面的多个计算函数对已有字段进行计算,得出新字段。
加、减、乘、除...
字符串剪切&替换&操作
转换控件中有三个关于字符串的控件,分别是剪切字符串、字符串操作、字符串替换。
- 剪切字符串:指定输入流字段裁剪的位置切除新的字段
- 字符串操作:取出字符串两端的空格和大小写切换,并生成新字段。
- 字符串替换:指定搜索内容和替换内容,如果输入流的字段匹配上搜索内容就进行替换生成新字段。
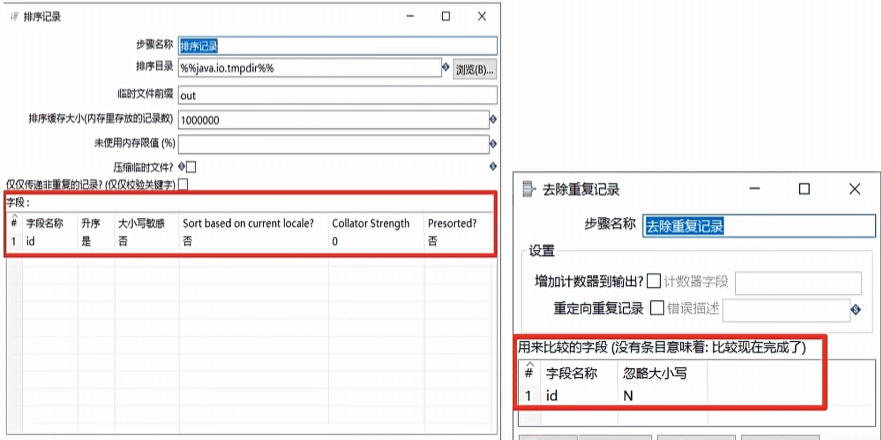
排序记录&去除重复记录
去除重复记录是去除数据流里面的相同的数据行。但次控件使用之前要求必须对数据进行排序,对数据排序采用排序记录。
唯一行(哈希值)
唯一行(哈希值)就是删除数据重复的行。此控件的效果和(排序记录+去除重复记录)的效果是一样的,实现原理不同,唯一行是给每一行的数据建立哈希值,通过哈希值来比较数据是否重复。因此唯一行去重效率较高,建议使用。

拆分字段
拆分字段就是按照分割符拆分成两个或多个字段。注意:字段拆分后原字段就会从数据流中消失。

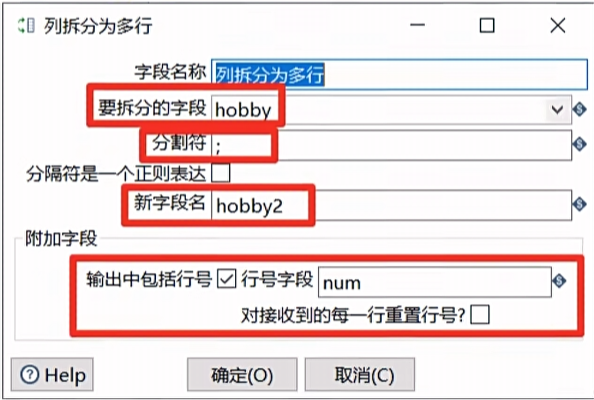
列拆分多行
列拆分为多行就是把指定字段按指定分割符拆分为多行,然后其他字段直接复制。
效果如下:

- 选择要拆分的字段
- 设置合适的分隔符
- 设置分割以后得新字段名
- 选择是否输出新数据的排列行号,行号是否重置
行扁平化
行扁平化就是把同一组的多行数据合并成一行,可以理解为列拆分为多行的逆向操作。
需要注意是扁平化控件使用的两个条件:
- 使用之前需要对数据进行排序
- ==每个分组的数据条数要保证一致==,否则数据会有错乱

列转行
列转行就是多列转一行,如果数据一列有相同的值,按照指定的字段,将其中一列的字段内容变成不同的列,然后把多行的数据转换为一行数据的过程。
效果如下:
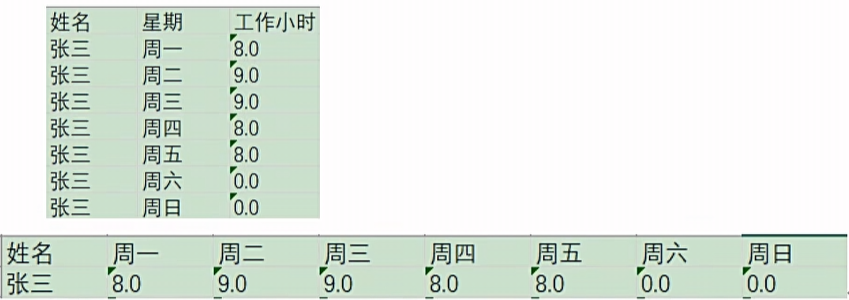
列转行之前数据流必须按照分组字段进行排序,否则数据会错乱!

- 关键字段:从数据内容变成列名的字段
- 分组字段:列转行,转变以后得分组字段
- 目标字段:增加的列的列名字段
- 数据字段:目标字段的数据字段
- 关键字值:数据字段查询时的关键字,也可以理解为key
- 类型:要给目标字段设置合适的类型,否则会报错
行转列
一行转为多列,就是把数据字段的字段名转换为一列,把数据行变成数据列。是列传行的逆向操作
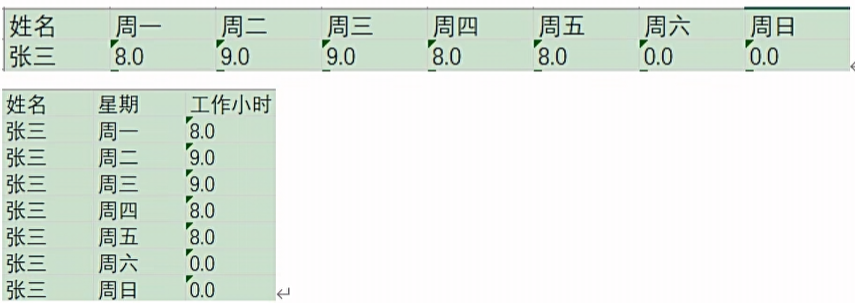

- Key字段:行转列,生成的列名字段名
- 字段名称:原本数据流中的字段名
- Key值:key字段的值,自己定义
- Value字段:对应key值的数据列的名称
应用控件
替换 Null 值
- 可以选择替换数据流中所有字段的null值
- 可以选择,在下面字段框里根据不同字段将null替换成不同的值
写日志
写日志控件主要是调试的使用使用,可以将数据流的每行数据打印到控制台,方便调试。

流程控件
用来控制数据流程和数据流向
Switch/case
最典型的数据分类控件,可以利用某一个字段的数据不同的值,让数据从一路到多路。
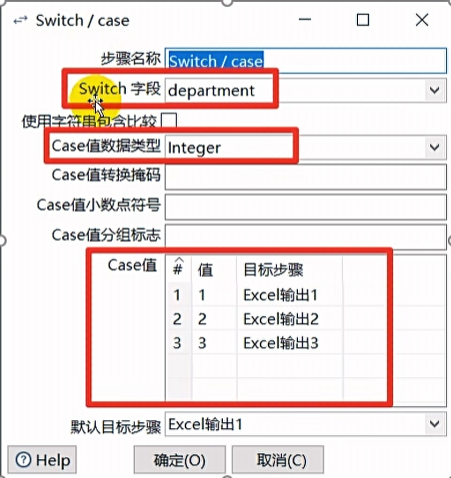
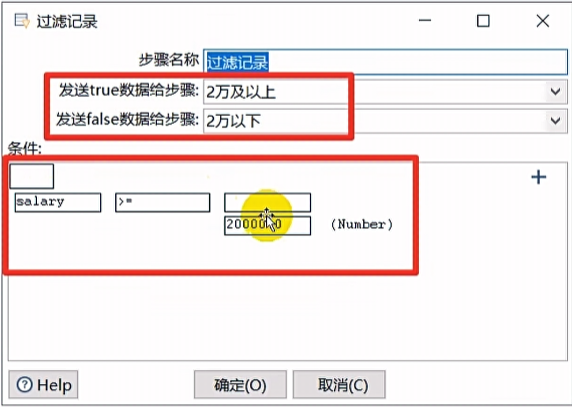
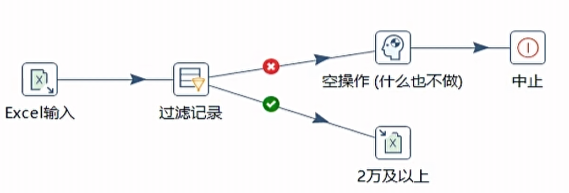
过滤记录
相当于 if-else,可以自定义输入一个判断条件,然后将数据流中的数据一路分为两路。
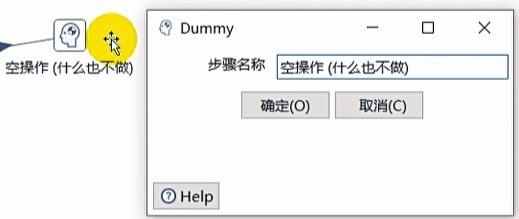
空操作
什么也不做,此控件一般作为数据流的终点。
中止
是数据流的终点,如果有数据流到此处,整个转换程序终止,并在控制台输出报错信息。一般用来校验数据或调试程序。

中止使用场景:
查询控件
查询数据源里的数据,并合并到主数据流中。
数据库查询
从数据库里面查询出数据,然后跟数据流中的数据进行左连接的一个过程。左连接的意思就是数据流中原本的数据全部都有,但数据库查询控件查询出来的数据不一定都会列出,只能按照输入的匹配条件来进行关联。

连接控件比这个用的多
流查询
流查询控件就是查询两条数据流中的数据,按照指定的字段做等值匹配。
注意:流查询在查询前把数据都加载到内存中。只能进行等值查询。
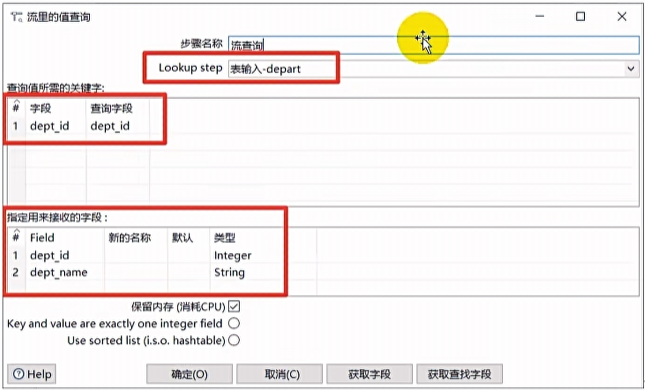
例子:

连接控件
连接分类下的控件一般都是将多个数据集通过关键字进行连接起来,形成一个数据集的过程。
合并记录
将两个不同来源的数据合并,这两个来源的数据分别为旧数据和新数据,该步骤将旧数据和新数据按照指定的关键字匹配、比价、合并。
注意:旧数据和新数据需要事先按照关键字段排序,并旧数据和新数据要有相同的字段名称。
合并后的数据将包括旧数据来源和新数据来源里的所有数据,对与变化数据,使用新数据替旧数据,同时在结果里用一个标示字段,来指定新旧数据的比较结果。

记录集连接
记录集连接可以对两个步骤中的数据进行左连接、右连接、内连接、外连接。此控件功能比较强大,企业做ETL开发会经常用到此控件,但需要注意在进行记录集连接之前,需要对数据集的数据进行排序,并且排序的字段还一定要选两个表关联的字段,否则数据错乱出现null值。

示例:

统计控件
提供数据的采样和统计功能
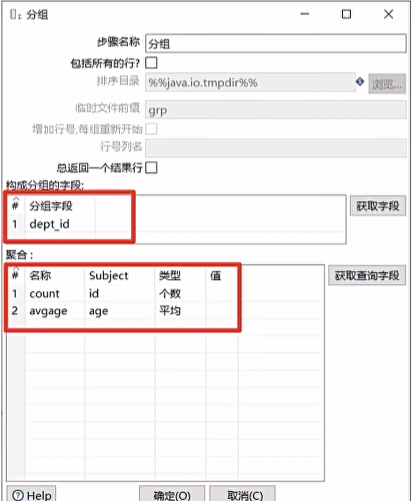
分组
分组控件功能类似与 GROUP BY,可以按照指定一个或几个字段进行分组,然后其余字段按照聚合函数进行合并计算。
注意:进行分组前,数据最好先进行排序
映射控件
用来定义子转换,方便代码封装和重用
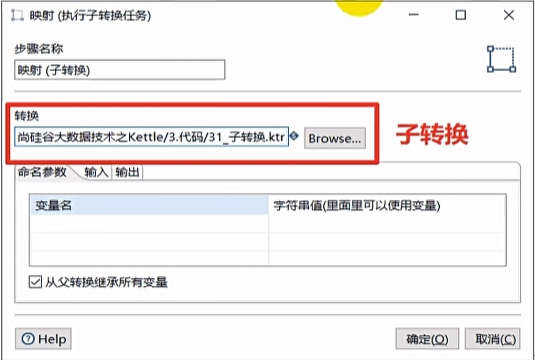
映射
映射(子转换)用来配置子转换,对子转换进行调用的一个步骤。
脚本控件
直接通过写程序代码完成一些复杂的操作
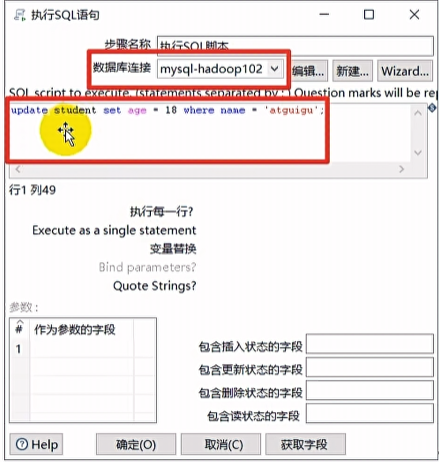
执行SQL脚本
执行SQL脚本控件就是连接到数据库里,执行自己写的sql语句。
Kettle 作业
一个作业包含一个或多个作业项。这些作业项以某种顺序来执行。作业执行顺序由作业项之间的跳(job hop)和每个作业项执行结果来决定。
作业项
作业的基本构成部分。如同转换的步骤,作业项业也可以使用图标的方式图形化展示。但作业有一下不同:
- 转换步骤与步骤之间是数据流,作业项之间是步骤流。
- 转换启动后,所有步骤一起并行启动等待数据行的输入,作业项是严格按照执行的顺序启动,一个作业项执行完成以后,再执行下一个作业项。
- 作业项之间可以传递一个结果对象(result object)。这个结果对象包含了数据行,他们不是以数据流的方式来传递。而是等待一个作业项执行完成,再传递给下一个作业项。
- 因为作业顺序执行的作业项,所以必须定义一个起点。有一个“开始”的作业项就是定义了这个点。一个作业只能定义一个。
作业跳
作业跳是作业项之间的连线。
有个小锁:不论上一个作业成功还是失败都会执行下一个作业
有个小对号:上一个作业执行结果为真,执行一下个作业
有个小叉号:上一个作业执行结果为假,执行下一个作业
Kettle 资源库
kettle 设计是跨平台使用
数据库资源库
数据库资源库是将作业和转换相关的信息存储在数据库中,执行的时候直接去数据库读取信息,很容易跨平台使用
- 点击右上角connect,选择 Other Resporitory
- 建立一个kettle-meta数据库
文件数据库
使用路径在本地创建一个本地资源库。
基本都涉及到啦,剩下不常用的自己探索吧~